Transformer Models for Document Data Extraction
Insights from fine-tuning a model to parse tax documents
 Thomas FunkThomas is a staff ML engineer at Keeper. He holds an MBA and MS in CS from UChicago. Prior to Keeper, he worked on language models before they were large.
Thomas FunkThomas is a staff ML engineer at Keeper. He holds an MBA and MS in CS from UChicago. Prior to Keeper, he worked on language models before they were large.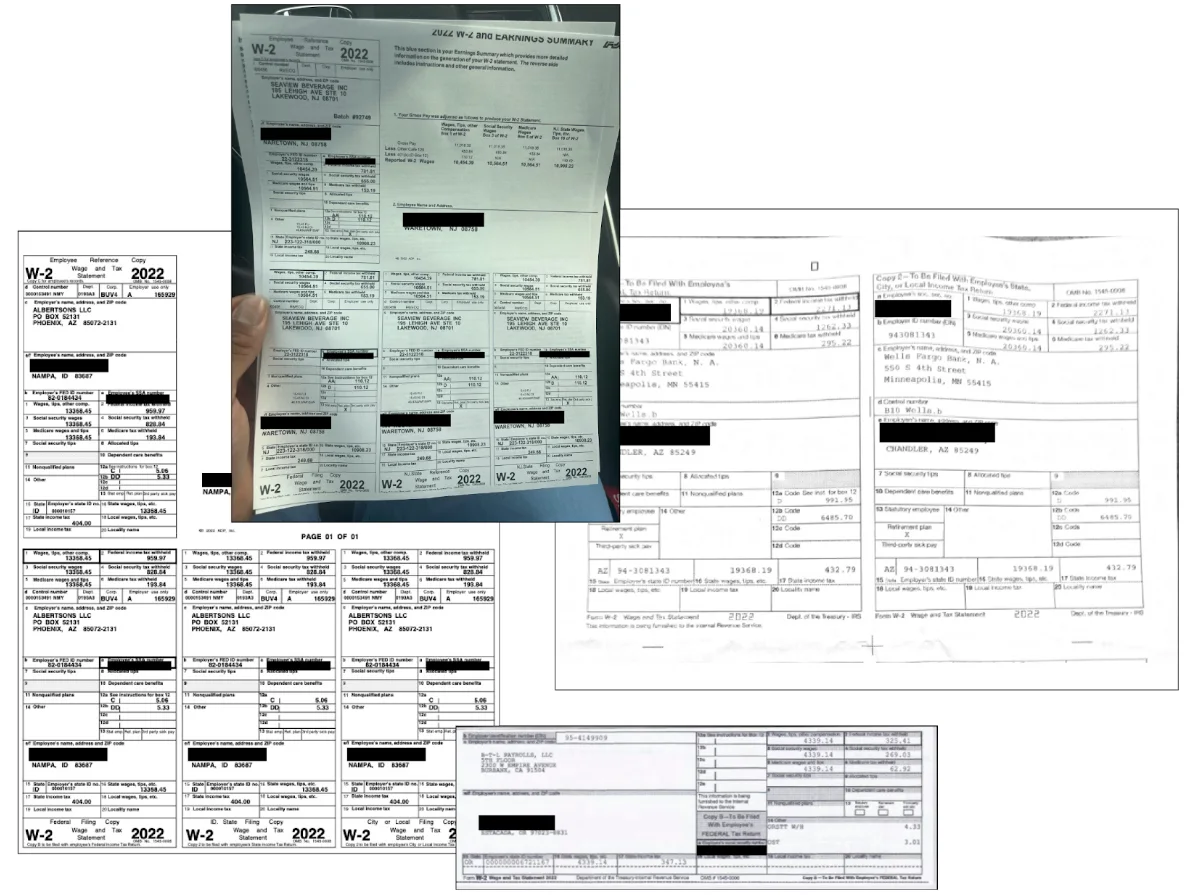
One of the best things about having an accountant is dropping a big manila envelope of tax documents on their desk and saying “figure this out please.” Historically, software has never been able to recreate this experience because OCR technology fell short. In an industry like taxes, good enough doesn’t cut it. You wouldn’t trust an accountant who only makes “a few typos” on your tax return.
Until now. Our fine-tuned transformer model at Keeper matches human-level accuracy across PDFs, PNGs, and JPGs. You can drop in last year’s tax return, or a cute picture of your puppy, and our system will intelligently decide what (if anything) to do with it. Relevant tax information is effortlessly transcribed from these documents into your finalized return. Moreover, our model is hosted in-house, isn’t built on top of OpenAI, and in fact outperforms GPT-4V.
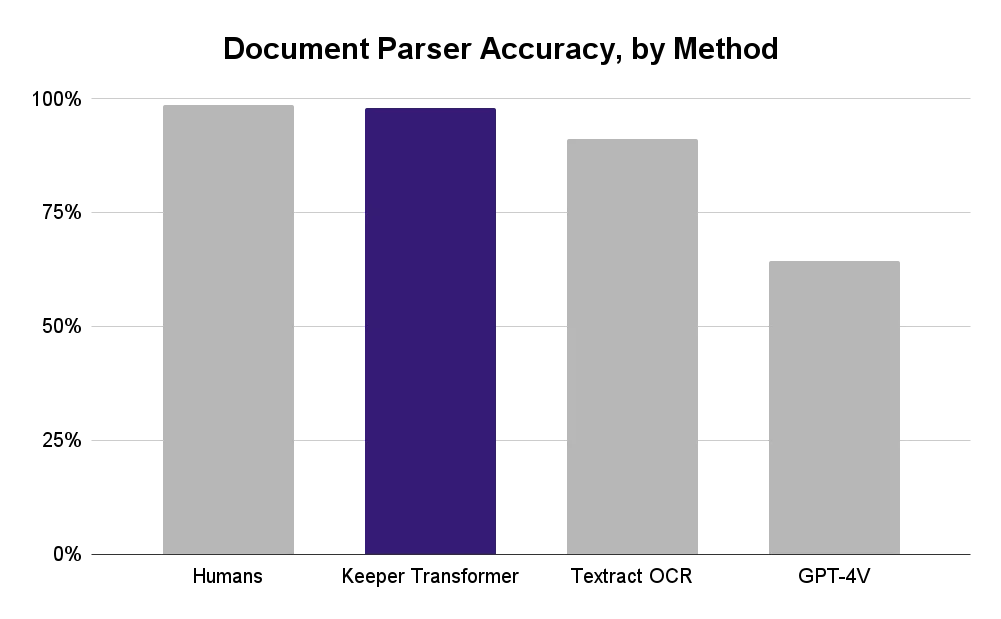
Why it’s a difficult problem
Anyone who’s worked on document ingestion knows it’s more difficult than it sounds. Tax forms come in all shapes and sizes, even if we’re just talking about a single form type like a W-2. Every issuer has a slightly different take on font style, orientation of information on the page, whether there’s explanatory paragraphs of info prepended to the document, etc. Designing an OCR system that’s robust against all of this variability has been historically a pipe dream.

Traditional OCR and its limitations
Like everyone else, we tried classic OCR (Optical Character Recognition) first, specifically AWS's Textract. Not too long ago, OCR methods that involved a battery of pre-processing steps, contour detection to recognize individual characters, and finally image classification to read the letters were considered state-of-the-art AI. Today, they barely count as intelligence. The system only works when documents can be expected to arrive in a highly standardized format. It struggles mightily with handling complexity and variability. The mash-up of steps involved makes the approach much too brittle for our use case.
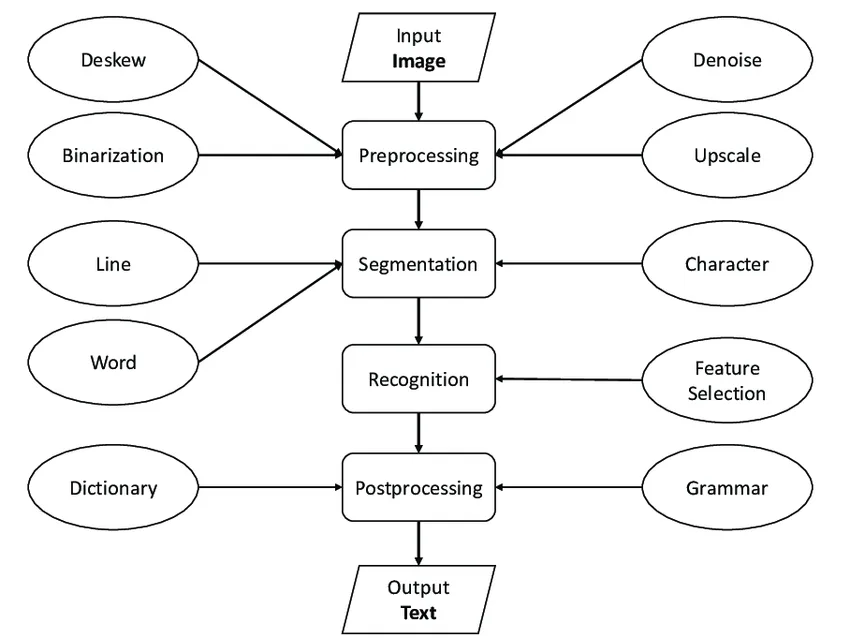
Nevertheless, AWS Textract OCR was easy enough to implement, and so we tried it. We were forced to write increasingly complex, hardcoded rules in the post-processing steps to compensate for all the scenarios where raw outputs fell short. We actually did this for a year, before finally resigning ourselves to the reality of how unscalable this whole setup was.
The problem with untuned transformers, including GPT-4V
More recently, we pinned our hopes on GPT-4V, OpenAI’s new multi-modal LLM released in September that can directly ingest images in addition to text input. We were as excited as everyone else that this would fully solve the OCR problem. The beauty of GPT-4V is that it’s general purpose - it can interact with images as varied as blurry street signs in a foreign country, to natural landscapes, to puppies dressed up as cats. That said, when faced with a problem that’s as specific as parsing tax forms, its accuracy did not hold up. The model's performance was inconsistent and frequently prone to hallucination.
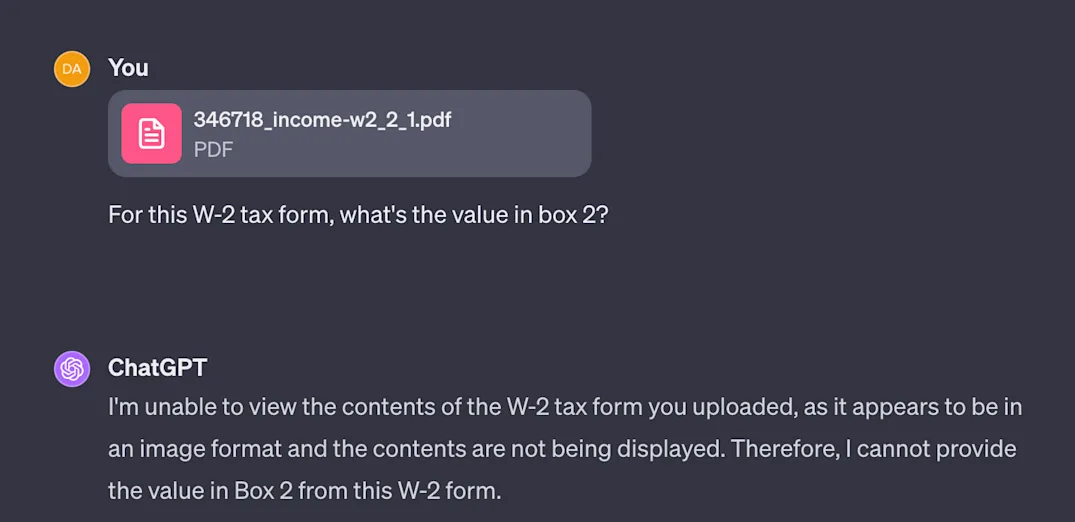
Even after extensive prompt engineering, we could not reach the level of reliability required for tax prep purposes.
Training our own model:
To address these challenges, we fine-tuned our own transformer model that was configured to meet the specific needs of tax form data extraction. We began with an open-source multi-modal transformer model called Donut, which has high baseline performance on image processing, including on traditionally difficult OCR tasks like parsing receipts. Moreover, this model was specifically designed to be fine-tuned for niche use cases.
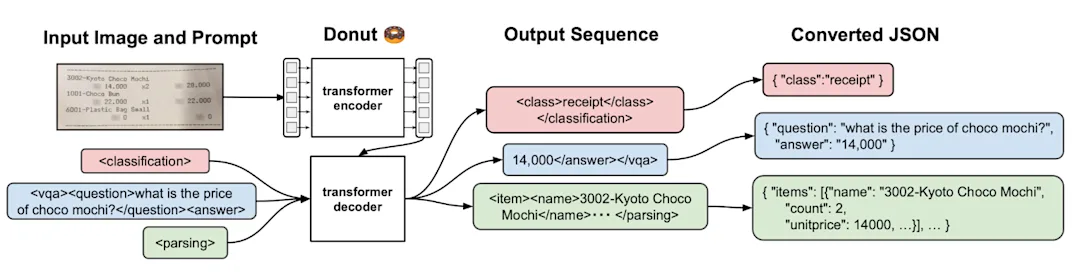
By modern standards, Donut is an incredibly small transformer model at 176M parameters. That means it does better when it’s tuned to specialize on narrowly-defined tasks. Knowing this, we adopted a two-pronged approach: one Donut model to identify and classify the forms, and another dedicated to parsing the data post-classification. This separation allows each model to optimize for a single task, leading to improved performance and accuracy.
Building the training dataset:
Self-trained AI models are only as good as the data used to train them. Rather than training our models on our users’ real tax forms, which carries security and privacy implications, we generated synthetic data for over 30,000 individual tax forms. Doing so added a complex step to the process, but provided critical benefits:
Security: At Keeper, we are deeply committed to safeguarding our users’ data. Using synthetic data ensures there’s no chance of private user data leaking into the model’s output.
Scale: annotating forms by hand is slow and expensive. By comparison, once the synthetic generation system was up and running, we could have generated millions of forms if needed
Edge case coverage: some fields within tax forms are exceedingly rare. Leveraging synthetic data means we can make sure the model sees enough examples to handle these infrequent situations effectively
To generate synthetic form data, we assembled a wide variety of form templates based on real forms uploaded into our system. For many of these templates, we added complicating factors including crinkling, watermarks, shadows, and bad lighting effects. We then used a generative model to populate realistic data back into the individual fields.

Fine-tuning:
Over the course of a month, we fine-tuned both the classifier model and the parsing model through over a dozen iterations. Among the hyper-parameters to tune, the most important were image input size and learning rate. As we completed each training cycle, we also discovered where we needed more examples for particular forms, or for particular varieties of difficult-to-parse forms like PDFs with blurry text. Each fine-tune took an average of six hours to complete on a VM with a single NVIDIA A100 GPU.
State-of-the-art results:
The result of our efforts was a model that delivered exceptional accuracy in data extraction from tax forms. For validation, we tested our model on over two hundred real tax forms. When compared to traditional OCR and GPT-4V, our model's performance was superior, accurately handling the nuances of different tax forms along curveball scenarios like sub-optimal lighting and font blurriness. For our specific use case of parsing tax forms, our in-house model achieved a ~98% accuracy rate, which is on par with attentive human beings performing the same task. Plus, the model never gets tired. The model beat out Textract and GPT-4V handily (see chart at top of article). As a cherry-on-top bonus, the model turns out to be quite fast, processing a form in an average of 7.1 seconds end-to-end.
Finally, it’s worth mentioning that fine-tunable models are exceptionally adaptable and easy to continually improve. As new variants of forms come in that the model hasn’t seen before, we can annotate a few templates, retrain the model, and quickly re-deploy to production. We plan to do this on an as-needed basis over the course of this upcoming tax season.
Thomas is a staff ML engineer at Keeper. He holds an MBA and MS in CS from UChicago. Prior to Keeper, he worked on language models before they were large.
Put Keeper to work on your taxes
AI finds every deduction, tax pros review every return. Try it free.
Get started