A new approach to live tax assistance, powered by LLMs
Higher customer satisfaction, 70% lower costs, zero user deception
 Tom MadsenTom is the Head of ML at Keeper. He holds a PhD in biostatistics from Harvard. Prior to Keeper, he taught statistics at a liberal arts college. He still likes wearing elbow patches.
Tom MadsenTom is the Head of ML at Keeper. He holds a PhD in biostatistics from Harvard. Prior to Keeper, he taught statistics at a liberal arts college. He still likes wearing elbow patches.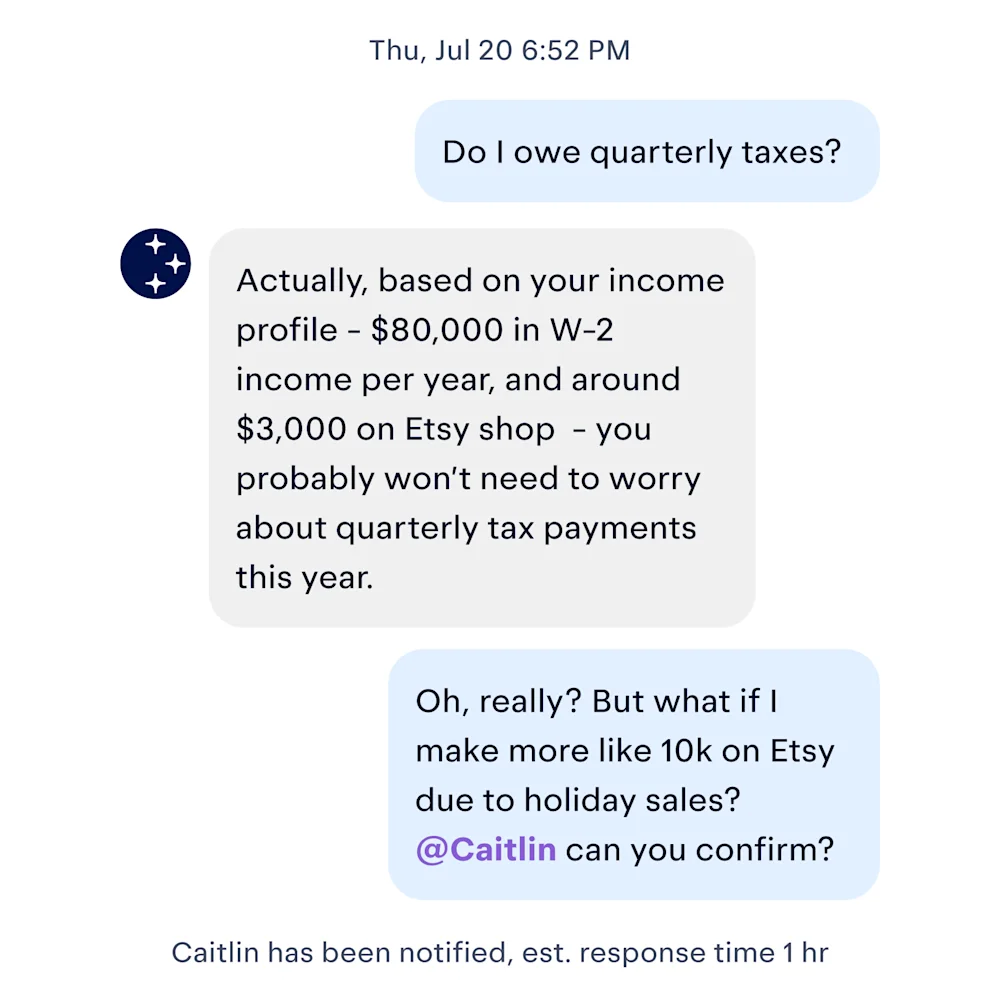
Tax advice from a bot? No way, we thought.
Then, in June, we launched our AI Accountant. For a space as language-intensive and well documented as tax law, it turned out that a well-tuned multi-agent model with the right embeddings was incredibly effective. In a blind test, V2 outperformed 80% of licensed tax professionals (i.e. human experts). It answered complex tax questions with 96% accuracy, compared to 94% for the human tax pros.
But AI Accountant was more of a research project than an actual product: it was slow, fragile, and bad at answering anything other than tax questions. To roll it out to our users, we had to teach the model to answer questions about our product, evaluate the quality of its own responses, and pull in human CX specialists when needed. These challenges are unsexy, but they have very meaningful business implications.
Over the past six months, we’ve worked tirelessly to overcome many of these challenges. This post outlines some of the lessons we learned along the way.
About our use case
Keeper is a tax filing software startup used by around 1M people in the US. One of the key value-adds of our service is the ability to ask difficult tax questions to a dedicated tax pro.
To make this possible at scale, we’ve always used language-based AI to help us sort through the easy questions and the hard ones. We were one of OpenAI’s earliest customers back in 2020, so by the time GPT-3.5 and 4 came around we had already spent over two years learning how to work with GPT-3.
Back in 2021, we used a hybrid system (shown below, on the left) that combined rules-based logic with fine-tuned LLMs to automate around 55% of inbound questions and pull in a human for the remainder.
Today, we have a very different approach (shown below, on the right). With many model / UI / operational iterations, we’ve substantially improved the quality of responses while simultaneously increasing their speed and reducing their cost. Put another way, we not only automated nearly everything, users love the new system much more even than having a dedicated human support rep. That’s progress.

Lessons learned along the way
In no particular order, below is a list of the biggest lessons we learned along the way. These are not intended to be gospel and will likely need to be updated every few months. Some of these may also be more applicable to our use case than yours.
Lesson 1: use a multi-agent infrastructure
One of the realities of any chat-based interface is that you have very little control over what kinds of questions users will ask. Users will distrust any system that cannot effectively respond to any question – you cannot ask users to segregate their questions. Inbound customer inquiries can range from specific questions about the product (e.g. “How can I change my payment method?”) to difficult questions about the tax code (e.g. “As the single non-resident alien owner of a single member LLC selling digital products online, is my income considered Effectively Connected Income?”).
Rather than trying to create one super-LLM, we’ve found it more effective to create different models that are especially effective at answering each type of question. For example, we had one team focus on just the difficult tax questions with our AI Accountant, and another team went and partnered with the CX team to optimize customer support answers. A classifier agent decides where to send the questions (or to break them apart!) and a synthesis agent merges and trims the answers.

Lesson 2: don’t cut corners on your eval system
Getting your model right will take iteration, and the only way to iterate your way to success is to first build an excellent eval system. If you can’t measure it, you can’t improve it.
There’s no need to reinvent the wheel here - we basically do exactly what OpenAI recommends. The hard part, surprisingly, isn’t building the system – but generating great eval questions and codifying what good answers should look like.
It’s a tricky project management problem because generating a good eval question list requires a skill set and knowledge of the company that the ML team typically doesn’t possess. For us, customer support questions are fairly easy – since you can just use existing cx macros. The hard part was generating a big enough list of correctly answered difficult tax questions. We needed at least 300 that were well vetted.
The problem is that the more difficult the question, the less you can rely on a simple system to generate the correct answers. For us, we had 5 separate certified tax professionals answer every question independently. Unfortunately, they agreed unanimously on only about half of the question. We then had to run a painstaking “truth finding” exercise on the remaining half – real tax law type research that sometimes even resulted in a decision that all 5 of the expert answers had been wrong.
It’s very very tempting to cut corners here – after all, you’re dealing with certified experts who are all used to being the authority on the matter. The problem is that as soon as you introduce any wrong answer into your eval system, you will begin dinging a model for being correct. Here’s an example of a question the LLM got right, but all 5 experts got wrong. Had we trusted the experts, we’d be punishing the model for being excellent. All iterations of the model that actually improved it would look worse - and changes that made the model dumber would look better. That’s not good.
Lesson 3: use a group chat framework
As we quickly learned, it’s not enough to build a fantastic model – getting users to discover it, engage with it, and trust it, is perhaps the biggest challenge of all.
The obvious options here are (1) pretend like the LLM is a human the whole time, or (2) separate the two, making humans harder to access. At Keeper, we’ve come to believe that both of those options are wrong.
Pretending your LLM is a human is not only deceptive, it creates real customer experience tradeoffs. For example, what happens when a user needs assistance outside of business hours? Do you care more about preserving the facade of a human and force them to wait, or do you keep insta-replying and show your cards? The idea that a human is always preferable is also, candidly, a bit small-minded. In just a few short years we’ll all be begging to speak with the fine-tuned LLM model and not the customer support rep.
On the other hand, today’s reality is that most consumers see “chatbots” as a worse solution than human support. Therefore, even if you’ve built a great agent, separating it from the human support channel sends a clear message that it’s second-class. Customers may very well not give it a chance to impress them.
That’s why we landed on and recommend the group chat framework. It’s transparent, and has the important advantage of being effectively mandatory. If a customer has a question, they can’t go around it. While that sounds sinister, what we’ve observed is that so long as you’ve actually built a great agent, you’ll be able to win the customer over quickly. In short, it creates a “show, don’t tell” dynamic. Talk is cheap, but a great answer delivered quickly puts an end to concerns.
Lesson 4: stay away from typical “assistant” tropes
From Microsoft’s Clippy to Apple’s Siri, consumers have been thoroughly underwhelmed by allegedly smart personified helpers that actually turn out to be a thin skin on top of a decision tree or voice search.

Assuming your model is actually smart, then the last thing you want to do is trigger users’ pattern recognition by introducing yourself like these bad assistants.
Resist the urge to personify it, don’t force it to recite pre-canned responses, and certainly don’t have it interrupt the user while they’re doing something else. Interruptions are the most sure-fire way to destroy trust. If the system is as smart as you say it is, then it should know that the user is busy doing something else right now. Instead, find contextual hooks – like one-click buttons that pre-fill questions when chat is the best way to explain something.
We learned this lesson by doing exactly that. The first version of our LLM-based assistant got very low engagement. The more we dug in and spoke with users, the more we realized that our presentation didn’t pass the “sniff test”. One glance, and users assumed it would be useless.
Lesson 5: build contextual hooks
When we first launched our AI assistant, we were disappointed not only by the low engagement rate, but also by the fact that users didn’t seem to even know what to ask. Instead of asking about capital loss carryover rules, they were messaging things like “help”, “hello” and “quarterly taxes”. No amount of model intelligence can turn those questions into magic moments.
Over time, we learned that the most effective way to get users to ask good questions (and therefore get them to the magic moment of a great response!) is by using contextual hooks – one-click ways to pre-fill a good, relevant question. For example, when a user isn’t sure whether a particular expense qualifies as a tax deductible business expense, they can press “Not sure” and the question will be posted to our AI. This is a nice meaty question that will access some of the personalization and intelligence that’s possible with a good LLM:

Lesson 6: you’ll have to rethink roles & responsibilities
No less tricky than all of the technical and user interface questions are those related to organizational structure.
Traditionally, there is enough of a technical barrier to AI models that a machine learning team has to serve as gatekeeper to all changes. However, LLMs are different because they are uniquely easy to work with.
Rather than a monolithic matrixed org structure that relies on a centralized machine learning team to make all the model changes, we found it most effective to treat that team more like a platform. Rather than fix each problem individually, the core team is responsible for making it easy for other teams to plug into their framework. This allows a feature team intimately familiar with a particular problem space to be the one responsible for getting the system to give a great answer.
The way we accomplished this logistically was for the platform teams to enable other teams to pass secret messages and prompt modifications to the core model. This then allowed feature teams to iterate quickly and independently without being blocked by the core infrastructure team’s backlog. In effect, this means product developers and product managers have to become well versed in how to work with LLMs, blurring the lines between machine learning and engineering.
Track and claim every eligible deduction with Keeper
Keeper scans your accounts for write-offs and files your return — with tax pros reviewing every one.
Try it freeRead next



Tom is the Head of ML at Keeper. He holds a PhD in biostatistics from Harvard. Prior to Keeper, he taught statistics at a liberal arts college. He still likes wearing elbow patches.
View full bio